En bref
Résumé
L’analyse des entretiens utilisateurs est une phase essentielle à la suite des entretiens utilisateurs qui permet d’identifier quels sont les problèmes les plus importants pour les solutionner ensuite.
Objectifs
Réussir à identifier un nombre réduit de problématiques très pertinentes pour ses utilisateurs sur la base d’entretiens utilisateurs qui ont généré énormément de données parfois contradictoires, notamment grâce à de l’IA pour gagner du temps !
Qu’est-ce que l’analyse des entretiens utilisateurs
Selon moi, l’analyse des entretiens est la phase la plus importante du processus de recherche utilisateur. Elle oriente drastiquement la suite du processus de conception (notamment via l’approche du Design Thinking), puisque c’est à ce moment que vous allez reformuler votre problématique initiale afin de vous lancer dans la phase d’idéation.
Pour être précis, vous allez devoir :
- Identifier les verbatims les plus pertinents de vos entretiens utilisateurs
- Reformuler ces verbatims et les regrouper en besoins et en habitudes
- En déduire des personas qui vous permettront de segmenter vos résultats
- Prioriser les problématiques les plus importantes persona par persona
Cette étape est la plus chronophage du processus de recherche utilisateur (aussi appelée phase de discovery). En effet, elle impose généralement de relire ses entretiens, de comprendre précisément quelles sont les émotions derrière les verbatims afin de bien les catégoriser, de les grouper de manière pertinente pour enfin en déterminer les 2-3 problématiques les plus importantes.
Pour bien comprendre, j’ai mis au point une formule qui permet de mesurer l’impact des différents besoins qui ressortent des entretiens que je cherche à traiter :
Impact = proportion de personnes concernées * score émotionnel ²
Pour les scores émotionnels négatifs, correspondant aux émotions déplaisantes
Impact = proportion de personnes concernées * score émotionnel ² / 2
Pour les scores émotionnels positifs, correspondant aux émotions plaisantes
Qu’est-ce que nous raconte cette formule ? Déjà elle impose de pouvoir déterminer finement le nombre de personnes discutant d’un besoin donné. Il est donc nécessaire d’être précis sur les verbatims à identifier auprès de vos différents utilisateurs. Cela veut donc dire que :
- il faut savoir sur quel persona il faut travailler
- il faut identifier les verbatims pertinents issus des entretiens
- il faut bien les catégoriser derrière
- tout cela prend du temps (généralement 10h pour 10 entretiens) car il faut le faire pour l’ensemble des verbatims afin de pouvoir avoir une proportion fiable (un rapport entre le nombre de verbatims de ce besoin par personnes et le total de participants)
- la manière de mener vos entretiens a un impact considérable sur vos résultats derrière. C’est d’ailleurs pour cette raison que je vous propose une page Comment poser les bonnes questions ? afin d’éviter au maximum les biais dans vos entretiens et formulaires.
Deuxièmement, cela impose d’avoir une évaluation des émotions derrière chaque verbatim puisque celle ci sera utilisée pour prioriser les problématiques. Cela veut donc dire que :
- il faut affecter un score à chaque verbatim
- il faut regrouper les besoins en fonction des émotions plaisantes ou déplaisantes
- il faut être en mesure d’utiliser les notes émotionnelles pour un besoin donné
Enfin, cette formule permet de mettre en avant le fait que les émotions plaisantes ont « moins d’impact » que celles déplaisantes. Cela veut dire qu’il faut beaucoup d’émotions plaisantes pour pouvoir faire en sorte de remonter dans les besoins les plus importants.
Tout ça pour quoi ?
Pour en ressortir une liste de besoins priorisés. Cette liste permet de se rendre compte des besoins qui semblent être les plus importants pour une cible donnée, en fonction de sa récurrence et de son impact émotionnel. Ce qui vous permet d’identifier les quelques problématiques qui paraissent être les plus importantes ! C’est bien pratique 🙂
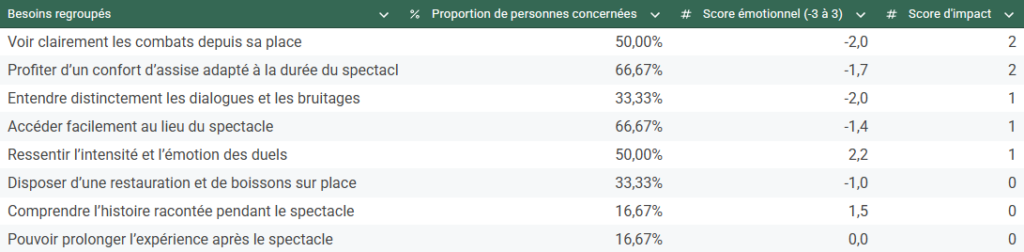
Mine de rien, la clarté qui ressort de ce type de tableau n’est vraiment pas évidente à atteindre. Bien souvent, on est submergé de centaines de verbatims différents, que l’on catégorise dans des dizaines de groupes ce qui participe à un sentiment de confusion induit par la quantité trop important de données.
Pourquoi utiliser l’IA pour analyser des entretiens
En quoi l’IA pourrait nous aider ici ? La réponse est simple, elle permet de gagner du temps. Et elle est très simple d’utilisation.
Mon objectif ici est de vous permettre de réaliser un maximum d’étapes de votre recherche utilisateur uniquement avec une IA générative de type ChatGPT. Un LLM (Large Modèle de Langage) qui est simple d’utilisation et accessible.
Faites attention tout de même à la confidentialité des données. Veillez à ne pas transmettre à des outils de ce type des informations qui sont confidentielles ou sensibles. Veillez aussi à anonymiser vos entretiens avant de les exploiter.
J’ai identifié 3 manières de l’utiliser pour gagner du temps tout en restant efficace.
Identifier et enrichir des verbatims (Gain de temps : ➕➕➕ / Qualité : ➕➕)
Une IA générative de type ChatGPT (qui est l’outil que j’utiliserais dans toute la suite du processus) est particulièrement efficace pour identifier des fragments de texte et de les enrichir. Ainsi, envoyer un entretien, qui a été retranscrit au préalable, pour en déterminer les verbatims les plus pertinents est redoutablement efficace.
Les + :
- Enorme gain de temps (1 min de traitement maximum versus 30 à 50 minutes à la main) pour détecter les différents verbatims pertinents et les enrichir (identification de l’émotion, reformulation en besoin, identification de l’étape du parcours utilisateur, etc.)
- Capacité à enrichir de manière très efficace, par sa capacité à « remplir les cases » qu’on lui demande de remplir
- Structuration du contenu pour le rendre facilement traitable derrière
Les – :
- Difficulté à avoir l’exhaustivité des verbatims pour un entretien (limite de la taille de la réponse)
- Difficultés à savoir à quel point tous les verbatims ont été identifiés (impossibilité de comprendre sa démarche de sélection)
- Mauvaise interprétation sur 5 à 15% des verbatims, soit par une erreur (- de 2% des cas, selon mon estimation personnelle), soit par une reformulation trop floue (5 à 15% des cas, selon mon estimation personnelle)
Faire des regroupements de besoins, d’habitudes et d’étapes (Gain de temps : ➕ / Qualité : ➕)
Une IA générative est relativement forte pour effectuer des regroupements (aussi appelés clustering). Cependant, ces modèles n’ont pas été entrainés pour cela et il existe des modèles d’IA plus efficace pour réaliser cette opération. Cependant, comme mon objectif est d’utiliser un seul outil, les résultats seront cohérents, mais peuvent laisser à désirer.
C’est pourquoi j’ai tendance à recommander de réaliser cette étape à la main puisque cela permet de mieux comprendre les données que l’on manipule tout en permettant d’ajuster au besoin.
Les + :
- Gain de temps important (1 min de traitement maximum versus 30 à 50 minutes pour l’ensemble des entretiens) pour regrouper des éléments déjà labellisés (besoins, habitudes, étapes)
- Capacité à identifier des résultats de manière efficace puisque les données sont fournies en entrée
- Cohérence des résultats en sortie car ils suivent une consigne unique
Les – :
- Difficulté à prédire le nombre de groupes attendu alors que cette donnée est dans la consigne initiale (il est très recommandé d’indiquer le nombre de groupes attendus en entrée pour plus d’efficacité)
- Difficulté à définir la granularité attendue et donc résultats qui peuvent laisser à désirer (et donc demande parfois plusieurs itérations)
- Grande variance des résultats malgré des consignes explicites (2 essais différents donneront très souvent 2 résultats différents)
Faire émerger des personas à partir des habitudes (Gain de temps : ➕ / Qualité : ➕➕)
A nouveau, l’analyse de données et la construction de groupes à la volée n’est pas la plus grande force des modèles de type LLM. Cependant, dans un persona, il est nécessaire d’ajouter des descriptions et du contexte, là où ChatGPT est très fort. Cela permet de particulièrement bien comprendre la segmentation proposée afin de l’évaluer efficacement.
Cette étape n’est pas essentielle dans la recherche utilisateur car les personas sont souvent identifiés a priori, c’est-à-dire dès les interviews. Cependant, il me parait utile de chercher à déterminer des personas sur la base de leur comportement et non pas que sur leur métier ou leur expérience (ce qui est souvent le cas). C’est pour cette raison que j’insiste sur la différenciation entre besoins (issus des émotions) et habitudes (issus des faits), afin de pouvoir faire émerger des personas à partir des entretiens pour pousser l’analyse encore plus loin.
Les + :
- Capacité à identifier des patterns difficile à repérer sans être expert de la donnée
- Capacité à segmenter l’ensemble des participants en personas, permettant une analyse bien plus fine
- Gain de temps assez important sur la génération des personas et leur association aux participants (1 min par itération versus 1h d’analyse pour un expert de la donnée)
Les – :
- Difficulté à prédire le nombre de personas attendus alors que cette donnée est dans la consigne initiale (il est très recommandé d’indiquer le nombre de personas attendus en entrée pour plus d’efficacité)
- Difficulté à évaluer la pertinence des personas proposés puisqu’en fonction des comportements choisis pour construire les personas, l’histoire derrière peut être différente
- Variance relativement importante des résultats malgré des consignes explicites (2 essais différents donneront souvent 2 résultats un peu différents)
Mes recommandations pour l’usage de l’IA dans l’analyse des entretiens utilisateur
Utilisez l’IA.
Au moins, essayez et constatez par vous même l’efficacité de cet outil, en particulier pour l’identification et l’enrichissement des verbatims. A titre perso, dans un cadre professionnel, j’utilise systématiquement cette méthode pour analyser mes entretiens étant donné le gain de temps que j’obtiens. Pour un résultat de très grande qualité.
Tout cela vous permettra d’avoir un grand tableau d’analyse qui référence l’ensemble de vos verbatims d’entretien, ce qui est facile à remplir et à réexploiter derrière.
A propos des traitements plus avancés liés aux regroupements automatiques, je suis un peu mitigé sur cela. Le fait de « mettre les mains dans le cambouis » en particulier en relisant l’ensemble des verbatims une fois les entretiens réalisés reste efficace pour une analyse plus poussée. Le risque ici est que, si vous manquez de recul, vous risquez d’avoir des regroupements qui sont incohérents par rapport à l’histoire que vous êtes en train de construire. Donc j’aurais tendance à faire particulièrement attention à cela. Je recommande mais en prenant le temps de relire systématiquement l’ensemble des résultats obtenus.
Enfin pour la détection des personas, je trouve cela très intéressant comme résultat et innovant. C’est à tester. L’avantage est que les consignes sont faciles à faire évoluer et l’itération est particulièrement simple. Je recommande donc.
La démarche pour analyser vos entretiens utilisateurs par IA (avec tous les prompts fournis)
Etape 0 : Réaliser et retranscrire ses entretiens
La première étape consiste à récupérer une version textuelle de ses entretiens. Il y a plusieurs méthodes pour cela :
- Utiliser un outil IA qui nous accompagne lors de l’entretien et qui retranscrit automatiquement l’échange (par exemple, l’outil Fireflies est efficace : https://fireflies.ai/)
- Utiliser les outils de retranscription intégrés dans les outils de visio de type Teams ou Google Meet. (généralement, de moins bonne qualité que les outils dédiés)
- Prendre des notes à la main, les plus fidèles possibles : noter exactement ce que dis la personne et les questions que l’on pose, le plus fidèlement possible.
- (Déconseillé) : Réécouter les entretiens et retranscrire à la main les entretiens. Cela permet de bien se remémorer ce qu’il s’est passé, mais c’est trop gourmand en temps à mes yeux.
Etape 1 : Identifier et enrichir les verbatims les plus pertinents (via un prompt spécifique)
L’enjeu de cette étape est de rendre systématique l’analyse de vos entretiens. Ce sont des choses que vous pouvez tout à fait faire à la main, mais ce n’est pas l’objectif ici.
En utilisant cette consigne (j’utiliserais de manière indifférenciée les termes prompt et consigne), vous allez récupérer 3 tableaux que vous allez copier/coller dans un fichier Excel / Google Sheets / Notion.
- une liste de participants
- une liste d’habitudes basées sur une première sélection de verbatims (basés sur des faits) selon le format suivant :
- « Quand » + déclencheur, « je » + description de ce que la personne fait (uniquement du concret et des choses factuelles que la personne a réalisé), « afin de » + enjeu
- L’objectif est de détecter toutes les habitudes du participant basé sur des éléments qu’il a déjà fait et qu’il fait régulièrement, puis de les reformuler
- une liste de besoins basés sur une deuxième sélection de verbatims (basés sur des émotions) enrichis de la manière suivante :
- quel est le contexte ?
- quelle est l’émotion associée ?
- quelle est la force de cette émotion ?
- quel est le besoin derrière cette émotion ?
- est-ce un besoin implicite ou explicite ?
- à quelle étape du parcours utilisateurs ce verbatim interview-t-il ?
Voici le prompt que je vous propose :
Tu es un analyste UX. Tu lis un entretien utilisateur complet.
Créé moi un tableau “Participant” d’une ligne contenant les éléments suivants :
- Nom du participant → insère le nom du participant que tu as déjà identifié et s’il n’est pas précisé, écrire “Participant” suivi de la date du jour ainsi que l’heure et la minute de la réponse LLM, heure française. Cet identifiant sera utilisé pour tous les autres champs “Nom du participant”
- Persona → Colonne vide
- Contexte → donne moi du contexte dans un paragraphe sur qui est la personne dans cet entretien
- Enjeux → quels sont les enjeux de cette personne ?
Créé moi un tableau “Habitudes du participant” qui contient toutes les habitudes (ce que la personne à déjà fait) mais surtout pas ses besoins (ce que la personne aimerait). Il en faut généralement au moins 6. Pour chaque habitude du participant, génère une ligne contenant les éléments suivants dans un tableau au format Markdown :
- Habitude → Rédige l’habitude au format "Quand" + déclencheur, "je" + description de ce que la personne fait (uniquement du concret et des choses factuelles que la personne a réalisé), "afin de" + enjeu : l'objectif est de détecter toutes les habitudes du participant basé sur des éléments qu'il a déjà fait et qu'il fait régulièrement, puis de les reformuler (par ex : Quand je joue en duo, j'interagis souvent avec mon coéquipier, afin d'optimiser notre partie)
- Groupe d'habitudes → Colonne vide
- Verbatims associés → 1 à 3 citations exactes du participant associés à cette habitude
- Nom du participant
- Persona → Colonne vide
Ensuite, créé moi un tableau “Emotions issues de l’entretien”. Identifie tous les verbatims contenant des émotions que tu trouves, il en faut généralement au moins 12, beaucoup plus si tu peux. Pour chaque émotion détectée dans l’entretien, génère une ligne contenant les éléments suivants dans un tableau au format Markdown :
- Verbatim → 1 citation exacte du participant
- Contexte → 1 phrase précise qui donne du contexte à ce verbatim pour le rendre clair immédiatement
- Niveau émotionnel (-3 = très déplaisant, +3 = très plaisant)" → une note de -3 à +3 avec -3 pour extrêmement déplaisant, -1 pour assez déplaisant, 0 pour neutre, +1 pour assez plaisant et +3 pour extrêmement plaisant et tous les intermédiaires. Repose toi sur le contexte pour bien évaluer.
- Emotion → synthèse factuelle de l’émotion détectée en gardant un niveau de précision important lié au domaine de l'entretien. Par exemple “Frustration liées aux données clients très dispersées”, “Déception du manque d’écoute de l’interlocuteur” ou “Appréciation de la promotion proposée”
- Reformulation en besoin → il faut reformuler le besoin issu de l’observation, tout en gardant un niveau de précision important lié au domaine de l'entretien. S’il n’y a pas de besoin, écris “-”.
- Groupe de besoins → Colonne vide
- Nature du besoin → Indiquer Explicite, Implicite ou Pas de Besoin (le besoin est-il exprimé implicitement ou explicitement ? si aucun besoin n’est détecté, indiquer “Pas de besoin”)
- Étape du parcours utilisateur → via un groupe nominal simple qui décrit l’étape du parcours utilisateur associée à cette émotion, en essayant de réutiliser les mêmes noms d’étapes si c’est pertinent. Par ex “Analyse des données” ou “Récupération du courrier”
- Groupe d'étapes → Colonne vide
- Nom du participant
- Persona → Colonne vide
Voici l’entretien à analyser :
Associez à ce prompt votre retranscription, soit en la copiant/collant ici si elle n’est pas très longue (prise de notes, entretien court) soit en chargeant directement un fichier de type Word qui sera interprété par l’outil.
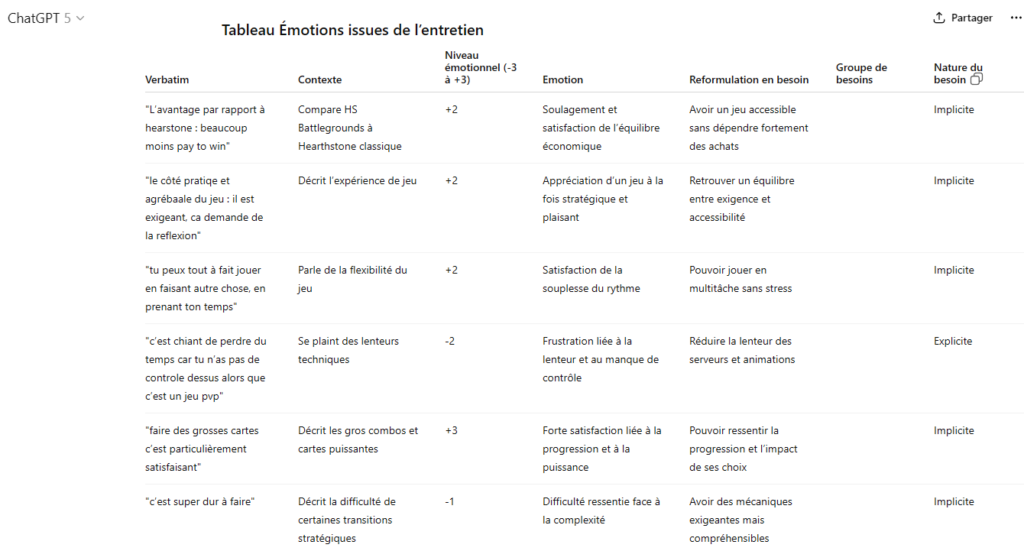
Créez vous un fichier Excel, Google sheets ou Notion avec 3 onglets et copiez-collez les tableaux concernés au bon endroit. Cela vous permettra d’avoir :
- l’onglet Participants contiendra la liste de vos participants avec du contexte
- l’onglet Habitudes contiendra la liste des habitudes en fonction de vos participants
- l’onglet Besoins contiendra la liste des émotions et besoins en fonction de vos participants
Attention, si vous avez l’impression de manquer de contenu lors de la génération des verbatims, je vous conseille d’utiliser le prompt suivant à l’issue d’une analyse. Cela vous permettra d’identifier d’autres émotions qui seraient passées sous le radar la première fois par l’outil.
As-tu terminé d'identifier toutes les émotions ? Si non, continue d'analyser les émotions au même formatRéalisez donc cette opération pour vos différents entretiens avant de passer à l’étape suivante.
Etape 2 : Regroupement des besoins
Dans votre fichier, vous remarquerez qu’il y a plusieurs colonnes vides. Les colonnes « Groupe de besoins », « Groupe d’habitudes » et « Groupe d’étapes » sont vides, ainsi que les toutes les colonnes « Persona ».
❗ Dans un soucis de simplicité, nous nous intéresserons d’abord uniquement à la colonne Regroupement des besoins. Les autres colonnes seront remplies via la partie « Pour aller plus loin » de ce guide.
L’objectif de la colonne « Groupe de besoins » est de rassembler des besoins similaires, étant donné que l’IA a fait du mieux qu’elle pouvait pour reformuler ces fameux besoins. Comme introduit précédemment, je vous invite à réaliser ce travail à la main. Effectivement, le fait de relire les verbatims issus des entretiens, de vérifier leur reformulation et d’ajuster les émotions permet de comprendre avec finesse la matière que vous manipulez, ce qui augmentera votre pertinence.
Ainsi, pour chaque ligne contenant un besoin reformulé, identifiez un groupe afin de réunir un maximum de besoins reformulés ensemble. L’objectif est d’avoir le moins de groupes possibles tout en gardant une pertinence élevée. J’essaye généralement de ne pas mélanger émotions déplaisantes et plaisantes, je privilégie le fait de séparer les émotions de nature différente dans des groupes de besoins distincts. L’idéal est généralement d’avoir 15 à 20 groupes de besoins au total.
Par exemple, pour les besoins suivants, « Mettre en place des outils et process simples pour faciliter la remontée d’insights » et « Partager les insights dans les rituels pour engager l’équipe », le groupe serait « Accéder et partager les insights clients ».
Maintenant, si vous décidez de passer par une étape « IA », vous pouvez utiliser le prompt suivant en ajoutant votre tableur au format Excel directement dans l’outil que vous utilisez. Il vous générera un fichier Excel que vous pourrez ouvrir.
Dans le fichier que je te fournis, l'objectif est de remplir la colonne groupe de besoins.
Pour cela, j'ai besoin que tu prennes l’ensembles des besoins et que tu les regroupe, afin que je puisse aller plus loin dans l'analyse derrière. Le nombre de groupes total doit représenter 15% de tous les besoins au maximum.
Etape 1 :
Sépare les besoins ayant associés aux émotions plaisantes (notes de 1 à 10) d’un côté et ceux associés aux émotions déplaisantes (-10 à 0) de l’autre
Etape 2 :
Réalise des regroupements d’abord basés sur les émotions déplaisantes
- Un regroupement a une proximité sémantique forte entre les différents besoins qu’ils le compose
- Un regroupement est nommé avec le format verbe à l’infinitif + complément afin qu'il soit facilement compréhensible et cohérent. Ce regroupement doit garder un niveau de précision important lié au domaine des besoins liés. (ex : “Maintenir une cohérence avec les standards des règles” pour un sujet sur les jeux de société)
- Un groupement ne peut pas avoir un seul élément
- Eviter d'avoir des regroupements "Autres" trop importants
Etape 3 :
Réalise la même chose pour les émotions plaisantes
Etape 4 :
Vérifie que chaque groupement ne contient que des émotions déplaisantes ou que des émotions plaisantes (pas de mix).
Si ce n’est pas le cas, réassocie les besoins intrus dans les groupes correspondants.
Si le nombre de groupes est trop important, regroupe des besoins plaisants avec d’autres plaisants. Fais de même pour les déplaisants.
Etape 5 :
Afin de vérifier, donne moi la liste de tous les besoins que tu as identifié et le nombre de verbatims associés dans le chat.
Enfin, fournis moi le fichier Excel avec la colonne groupe de besoins remplie avec exactement les mêmes éléments fourni dans la liste ainsi qu’avec les mêmes associations.
Contraintes
- Ne pose aucune question, ne demande aucune confirmation.
- Ne donne que le résultat final structuré, sans introduction ni conclusion.
- Affiche la liste des besoins puis le fichier Excel à télécharger
Copiez alors la colonne « Groupe de besoins » que vous récupérez et collez la dans votre fichier initial, l’ordre est conservé.
Une fois ceci fait, je vous incite fortement à relire les résultats et à ajuster les groupes en fonction de la qualité que vous cherchez à avoir.
Etape 3 : Identifier les problématiques les plus récurrentes
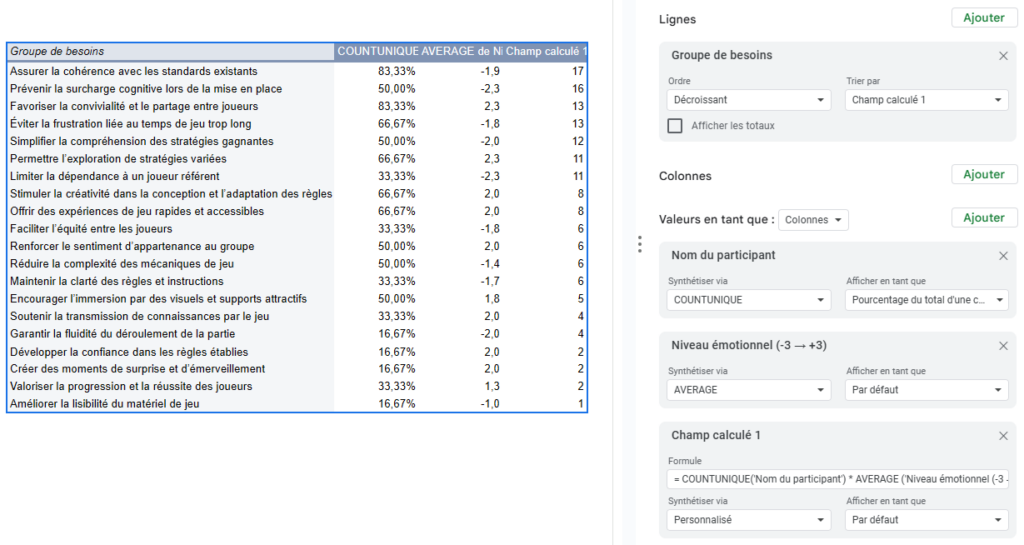
Là ça devient un peu plus sport. Si vous utilisez Notion, vous pouvez utilisez des tables croisées. Pour les autres, vous allez utiliser un Tableau Croisé Dynamique (Tout le paramétrage est indiqué dans l’image ci-dessous).
- Sélectionnez tout votre tableau de Besoins (CTRL + A)
- Cliquez sur Insertion, puis Tableau Croisé Dynamique
- Ajoutez en ligne l’élément « Groupe de besoins »
- Ajoutez en valeur « Nom du participant » et paramétrez le sur le comptage des occurences uniques (COUNTUNIQUE dans Google sheets) puis afficher ceci en pourcentage d’une colonne
- Ajoutez en valeur « Niveau émotionnel (-3 → +3) » et paramétrez le sur AVERAGE pour avoir la moyenne des notes
- Ajoutez un champ calculé, indiquer le champ « Synthétiser via » Personnalisé et indiquez la formule suivante (dans Google sheets) :
= COUNTUNIQUE(‘Nom du participant’) * AVERAGE (‘Niveau émotionnel (-3 → +3)’) ^ 2 * (0,75-0,25 * SIGN(‘Niveau émotionnel (-3 → +3)’))- Il s’agit de la formule présentée précédemment au format calcul en une ligne. Pensez à mettre à jour les champs si vous avez modifié les noms de colonnes
- Les plus attentifs auront remarqué que cette formule affiche le nombre de participants et non la proportion. Ce n’est tout simplement pas calculable dans Google Sheets et le résultat revient au même
- Triez votre tableau en fonction du « Champ calculé » par valeur décroissante.
- Observez l’ordre de priorisation qui vous met en avant les besoins les plus présents parmi vos participants croisés avec les émotions les plus fortes
Etape 4 : En tirer des problématiques
Sélectionnez les 5 besoins qui reviennent le plus et tirez-en 5 problématiques au format « Comment pourrions-nous ».
Cela vous permettra d’avoir une liste de besoins prioritaires et émotionnellement impactants pour votre cible. Cette liste de problématiques pourra être challengée avec le reste de l’équipe afin qu’elle se positionne sur ce qu’elle a envie de faire vis-à-vis de ces problématiques.
Pour aller plus loin : la segmentation par persona
Comme expliqué plus tôt, il est possible de faire émerger des personas à partir de vos entretiens. Pour cela, il va falloir d’abord regrouper les habitudes pour effectuer un traitement sur ces derniers afin d’en faire ressortir des personas. Il s’agit de regrouper vos habitudes afin de réduire leur nombre en un ensemble plus cohérent (notamment pour éviter d’avoir trop de fois la même idée sous des termes différents).
Comme pour les besoins, vous pouvez faire ce travail à la main afin d’avoir la meilleure qualité possible.
Sinon, le premier prompt que je vous propose, à associer avec votre fichier que vous avez exporté au format Excel, est le suivant.
Dans le fichier que je te fournis, l'objectif est de remplir la colonne groupe d'habitudes. Pour cela, j'ai besoin que tu regroupes toutes les habitudes similaires ou proches sémantiquement dans cette colonne, afin que je puisse aller plus loin dans l'analyse derrière. Je souhaite que ces groupes garde la même structure sémantique que les habitudes initiales, c'est à dire que leur formulation reste sous forme de quand / je fais / afin de. Il serait préférable que tu cherches d'abord à créer des clusters entre toutes les habitudes avant de remplir le tableau directement. Peux-tu me donner ce tableau avec la colonne groupe d'habitudes remplie ? Ne me demande pas de confirmation et livre moi directement le fichier.
Ceci vous fournira un fichier Excel que vous pourrez ouvrir et vous pourrez copier / coller la colonne « Groupe d’habitudes » dans votre fichier.
Une fois ceci fait (ou que vous avez fini de remplir la colonne « Groupe d’habitudes » du fichier), réexporter votre fichier et associez le au prompt suivant.
Tu es un expert en recherche utilisateur et segmentation comportementale. Travaille uniquement à partir des groupes d’habitudes distinctes pour construire les personas. Suis exactement les étapes ci-dessous.
1. Préparation déterministe
- Construis la matrice Participants × Groupes d’habitudes (1/0).
- Pour chaque participant, liste ses groupes d’habitudes (texte exact du fichier).
2. Construction des personas
- Contraintes pour la création de persona
- Taille minimale : il est absolument impossible qu’un persona ne contienne qu’1 seul participant
- Habitudes en commun : un persona est constitué lorsque qu’il partage plus de 2 habitudes en commun entre participants
- Unicité participant - persona : chaque participant appartient à un seul persona. En cas de multi-correspondance, affecte-le au persona où il partage le plus d’habitudes
- Nombre de personas fixe : Crée exactement 2 personas
- Regroupe les participants en persona
3. Contrôles de cohérence
Vérifie que les conditions sont bien remplies et modifie les personas si ce n’est pas le cas :
- somme des participants = total,
- 0 participant en double,
- aucun persona < 2 participants,
4. Crée un tableau “Personas”. Pour chaque persona, génère une ligne contenants les éléments suivants dans un tableau au format Markdown :
- Persona : nom clair et descriptif du persona et non du groupe (ex : Conducteur experimenté et non Les conducteurs expérimentés)
- Description : une description synthétique (50 mots max) incluant : ce qui le distingue et ce qu’il ne fait pas par rapport aux autres personas
- Participants associés : séparés par un saut de ligne
- Habitudes en commun : séparées par un saut de ligne.
- Explication du choix des participants : explique de manière détaillées pourquoi ce groupe comporte les participants choisis de manière accessible et pourquoi les autres en sont exclus
5. Export
- Dans l’onglet “Participants”, complète la colonne “Persona”
- Ajoute un nouvel Onglet nommé Personas comprenant le tableau Personas
- Fournis le fichier Excel mis à jour
Contraintes
- Utilise exactement les libellés du fichier (pas de reformulation d’habitudes).
- Ne pose aucune question, ne demande aucune confirmation.
- Ne donne que le résultat final structuré, sans introduction ni conclusion.
- Affiche le tableau Personas puis le fichier Excel à télécharger
Celui ci vous permettra de récupérer :
- une liste de 2 personas que vous pouvez ajouter dans votre fichier dans un nouvel onglet « Personas »
- vous pouvez changer le nombre de personas attendu directement dans la consigne
- un fichier Excel associant vos différents participants à des personas
- Copiez la liste de personas de l’onglet Participants dans votre fichier
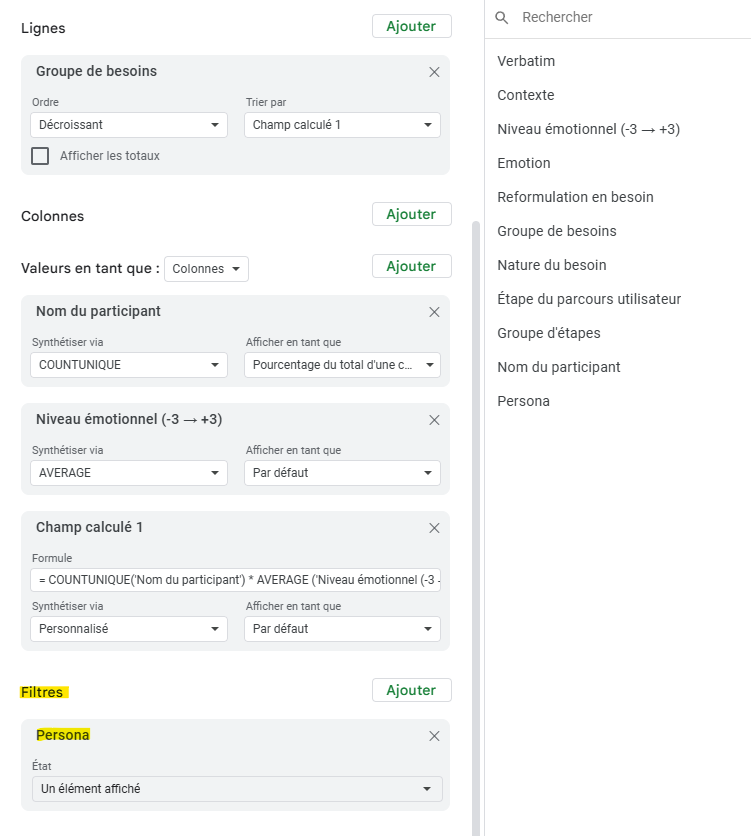
Victoire, vous avez donc une liste de participants associés à des personas ainsi qu’une liste de personas avec une description et des habitudes en commun. Mais vous pouvez aller un cran plus loin. Dans les onglets Besoins et Habitudes, sélectionnez les champs vides de la colonnes Persona et ajoutez la formule suivante :
=XLOOKUP(INDIRECT("RC[-1]";0); Participants!$A:$A; Participants!$B:$B; "Non trouvé")
Cette formule permet d’afficher dans la colonne Persona le persona relié au bon participant. Pratique pour pouvoir filtrer.
En effet, vous pouvez alors retourner dans votre Tableau dynamique et ajouter l’élément « Persona » dans la partie « Filtres ». Celui ci vous permettra ainsi de mettre en avant seulement les besoins associé à un persona donné.
Pour aller plus loin : l’aide à la création de l’experience map
La dernière colonne qui reste vide est celle nommée « Groupe d’étapes ». Il s’agit de regrouper vos étapes afin de réduire leur nombre en un ensemble plus cohérent (notamment pour éviter d’avoir trop de fois la même idée sous des termes différents).
Comme précédemment, vous pouvez faire ce travail à la main afin d’avoir la meilleure qualité possible.
Sinon, le prompt que je vous propose, à associer avec votre fichier que vous avez exporté au format Excel, est le suivant.
Dans le fichier que je te fournis, l'objectif est de remplir la colonne groupe d’étapes. Pour cela, j'ai besoin que tu regroupes toutes les étapes similaires ou proches sémantiquement dans cette colonne, afin que je puisse aller plus loin dans l'analyse derrière. Je souhaite que ces groupes garde la même structure sémantique que les étapes initiales, c'est à dire que leur formulation reste sous forme d’un groupe nominal simple qui décrit l’étape du parcours utilisateur associée à cette émotion. Il serait préférable que tu cherches d'abord à créer des clusters entre toutes les étapes avant de remplir le tableau directement.
Il me faut 12 étapes au maximum. Tu peux ajouter une catégorie Autre si nécessaire.
Peux-tu me donner ce tableau avec la colonne groupe d’étapes remplie ? Ne me demande pas de confirmation et livre moi directement le fichier.
Ceci vous fournira un fichier Excel que vous pourrez ouvrir et copier / coller la colonne « Groupe d’étapes » dans votre fichier.
A partir de ce moment, vous pouvez créer un nouveau tableau dynamique selon les critères suivants :
- En ligne, ajoutez le Groupe d’étapes
- En valeurs, ajoutez le niveau émotionnel, que vous paramétrez sur la moyenne des notes (Choix de AVERAGE ici)
- En filtre, ajoutez le filtre persona
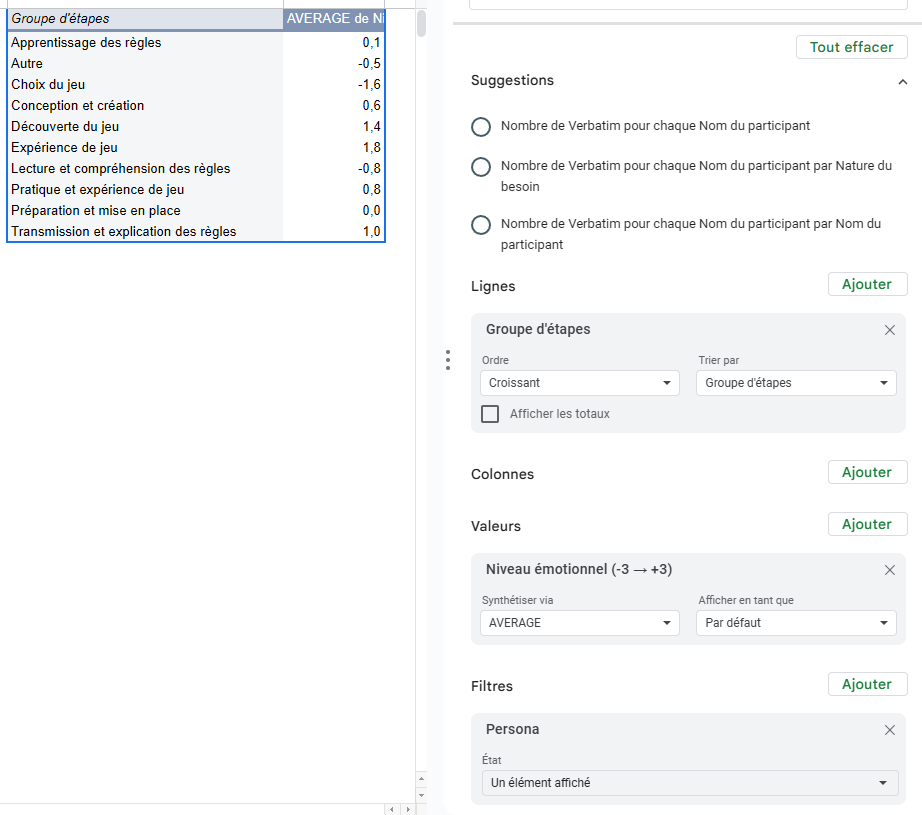
Cela vous permet alors de visualiser les différentes étapes de votre experience map (à réordonner dans un autre livrable) et vous permet d’avoir un score émotionnel précis pour chacune de vos étapes.
C’est une aide pratique pour accélérer la création. Vous pouvez même accéder directement aux verbatims et besoins en double cliquant sur une des notes du score émotionnel (pensez à supprimer le nouvel onglet créé une fois la lecture terminée, le cas échéant).
Le mot de la fin
Bon, on y est. Petit à petit, vous devenez de sacrés experts de la donnée quand même, vous trouvez pas ?
Si vous avez tout suivi, pas à pas, normalement vous avez un tableur qui contient toute votre recherche utilisateur ou presque, avec :
- tous vos verbatims hyper structurés
- vos personas construits sur la base de leurs habitudes
- vos problématiques priorisées par persona
- les différentes étapes de votre expérience map avec la note émotionnelle associée
Ca en jette non ? Tout ça en moins d’1h, sans relecture. Mais il FAUT relire, donc prévoyez plutôt 4 bonnes heures devant vous pour vérifier tous vos résultats.
Ce que je vous livre là, j’aurais rêvé de l’avoir il y a quelques années. Vous n’imaginez pas le temps gagné par la structure que je vous propose et par l’automatisation du remplissage via l’IA. Je me jette un peu des fleurs, c’est vrai, mais il y a eu beaucoup de travail pour arriver à ce résultat 🙂
Si vous devez vous souvenir de 3 trucs
- Prenez le temps d’identifier les verbatims les plus pertinents basés sur les émotions de vos participants, c’est le plus important
- Reformulez ces verbatims en besoin, ça vous aidera pour construire vos problématiques derrière
- Associez à vos verbatims une note émotionnelle, ça vous aidera pour votre priorisation derrière
La bise à vous qui êtes arrivés jusqu’ici 😉